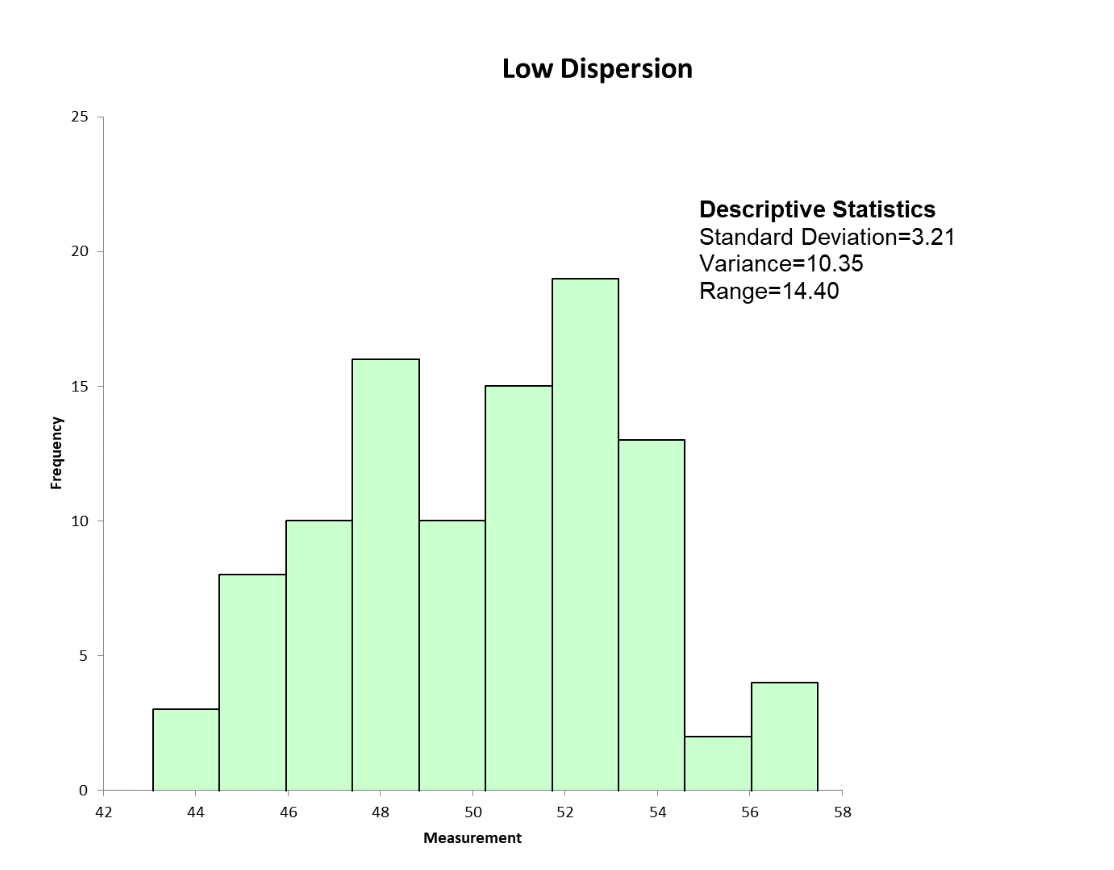
In today’s data-driven world, the ability to analyze and interpret data effectively is at the core of countless industries. One concept that plays a pivotal role in this process is data dispersion. Whether you're working in finance, healthcare, technology, or education, understanding data dispersion is fundamental to making informed decisions. It helps organizations identify patterns, measure variability, and gain insights that drive innovation and efficiency.
Data dispersion refers to the spread or distribution of data points within a dataset. It provides valuable information about how much variation exists in the data, offering a deeper understanding of its underlying structure. Without analyzing dispersion, data could be misleading, as averages and other central measures may not always tell the full story. For instance, two datasets with identical averages can have dramatically different dispersion levels, leading to vastly distinct conclusions.
In this comprehensive guide, we’ll delve into every aspect of data dispersion, from its definition and importance to the various methods and tools used to measure it. We’ll also explore real-world applications, challenges, and the role of software in analyzing dispersion. Whether you’re a data scientist, a business analyst, or simply someone curious about statistics, this article will equip you with the knowledge to navigate the fascinating world of data dispersion with confidence.
Read also:Jimmie Walkers Net Worth Behind His Financial Success
Table of Contents
- What is Data Dispersion?
- Why Data Dispersion Matters
- Types of Data Dispersion
- Measures of Data Dispersion
- Range: A Simple Measure of Spread
- Variance: Understanding Data Variability
- Standard Deviation: A Key Metric
- Interquartile Range (IQR): Measuring Middle Spread
- Real-World Applications of Data Dispersion
- Challenges in Measuring Data Dispersion
- Tools and Software for Analyzing Data Dispersion
- Visualizing Data Dispersion
- Data Dispersion vs. Central Tendency
- Future Trends in Data Dispersion Analysis
- FAQs About Data Dispersion
- Conclusion
What is Data Dispersion?
Data dispersion refers to the extent to which data points in a dataset are spread out or clustered together. Essentially, it measures variability within the data, helping statisticians and analysts understand the distribution of values. Dispersion is critical because it provides context that central tendency measures, like the mean or median, cannot offer on their own.
For example, if two datasets have the same average but different levels of dispersion, their interpretations would differ. Dataset A may have values tightly clustered around the mean, implying consistency, while Dataset B could have widely scattered values, indicating variability. By analyzing data dispersion, we can better gauge the reliability and predictability of datasets.
Mathematically, data dispersion can be quantified using various measures, such as range, variance, standard deviation, and interquartile range. These metrics help us understand the spread of data, whether it's tightly packed or widely scattered, and are essential for making accurate predictions and assessments.
Why Data Dispersion Matters
The importance of data dispersion cannot be overstated in statistical analysis and data science. It plays a pivotal role in understanding datasets, identifying anomalies, and making informed decisions. In real-world scenarios, data dispersion helps businesses evaluate risks, optimize strategies, and improve performance.
Consider a company analyzing customer satisfaction survey results. If the average satisfaction score is 8 out of 10, it might seem like customers are generally happy. However, a closer look at data dispersion could reveal that while some customers gave a perfect 10, others gave a dismal 5. This variability would indicate underlying issues that need to be addressed. Without analyzing dispersion, the company might overlook critical insights.
Moreover, data dispersion is crucial in fields like finance and healthcare, where understanding variability can mean the difference between success and failure. For instance, in finance, high dispersion in stock prices could indicate market volatility, impacting investment decisions. In healthcare, analyzing the spread of patient recovery times can help identify factors affecting treatment efficacy.
Read also:A Look Into The Bond Between Kim Porter And Tupac
Types of Data Dispersion
Data dispersion can be classified into two main types: absolute dispersion and relative dispersion. Each type serves specific analytical purposes and offers unique insights into the data.
Absolute Dispersion
Absolute dispersion measures the spread of data using fixed units, such as dollars, days, or points. Common measures of absolute dispersion include:
- Range
- Variance
- Standard deviation
These metrics provide a direct understanding of how data points deviate from the central value.
Relative Dispersion
Relative dispersion, on the other hand, expresses variability as a proportion or percentage, making it easier to compare datasets with different units or scales. Common measures of relative dispersion include:
- Coefficient of Variation (CV)
- Index of Dispersion
Relative measures are particularly useful in cross-sectional analyses, where datasets with varying scales must be compared.
Measures of Data Dispersion
Several statistical measures are used to quantify data dispersion. These metrics provide insights into the spread of data and help analysts draw meaningful conclusions. Below are the primary measures of data dispersion:
1. Range: The simplest measure of dispersion, calculated as the difference between the maximum and minimum values in a dataset.
2. Variance: Measures the average squared deviation of each data point from the mean. It highlights variability within the dataset.
3. Standard Deviation: The square root of variance, providing a more interpretable measure of spread in the same units as the data.
4. Interquartile Range (IQR): Focuses on the spread of the middle 50% of data, minimizing the impact of outliers.
Each measure has its advantages and limitations, making it essential to choose the right one based on the specific context and objectives of the analysis.
Range: A Simple Measure of Spread
The range is one of the simplest and most intuitive measures of data dispersion. It is calculated by subtracting the smallest value in the dataset from the largest value. While the range provides a quick overview of the data's spread, it is highly sensitive to outliers, which can skew results.
For example, consider a dataset of monthly temperatures in a city: [30, 32, 31, 29, 35]. The range would be 35 - 29 = 6. Here, the range indicates that the temperature varies by 6 degrees over the month. However, if an outlier, such as 50, is added, the range increases dramatically to 50 - 29 = 21, potentially leading to misinterpretation.
Despite its limitations, the range remains a valuable tool for gaining initial insights into data dispersion, especially in exploratory data analysis.
Variance: Understanding Data Variability
Variance is a more robust measure of data dispersion, capturing the average squared deviation of each data point from the mean. By squaring the deviations, variance emphasizes larger differences, making it particularly useful in datasets with significant variability.
The formula for variance is:
- Variance (σ²) = Σ (xᵢ - μ)² / N
Where:
- Σ: Summation symbol
- xᵢ: Individual data points
- μ: Mean of the dataset
- N: Number of data points
Variance is widely used in fields like finance, where understanding risk and volatility is critical. However, its squared units can make interpretation challenging, leading to the use of standard deviation as a complementary measure.
Standard Deviation: A Key Metric
Standard deviation is arguably the most commonly used measure of data dispersion. It is the square root of variance, making it more interpretable as it shares the same units as the original data. Standard deviation provides a clear understanding of how much individual data points deviate from the mean.
For instance, in a dataset with a mean income of $50,000 and a standard deviation of $10,000, most data points would fall within $40,000 to $60,000 (mean ± standard deviation).
Standard deviation is a cornerstone in fields like quality control, where it helps monitor process consistency, and in finance, where it aids in assessing investment risk.
Interquartile Range (IQR): Measuring Middle Spread
The Interquartile Range (IQR) is a measure of dispersion that focuses on the middle 50% of data, making it less sensitive to outliers than the range. It is calculated as the difference between the third quartile (Q3) and the first quartile (Q1):
IQR = Q3 - Q1
IQR is particularly useful in identifying outliers and understanding the central spread of data. For example, in a dataset of exam scores: [50, 60, 70, 80, 90], Q1 = 60, Q3 = 80, and IQR = 80 - 60 = 20. This indicates that the middle 50% of scores span a range of 20 points.
By focusing on the interquartile range, analysts can gain insights into the dataset's core variability without being influenced by extreme values.
Real-World Applications of Data Dispersion
Data dispersion is a versatile concept with applications across a wide range of industries. In business, it helps organizations assess market trends, customer behavior, and operational efficiency. In healthcare, it aids in understanding patient outcomes, treatment variability, and disease progression.
For instance, in education, analyzing the dispersion of test scores can reveal disparities in student performance, guiding targeted interventions. Similarly, in sports, understanding variability in player performance can help coaches devise better strategies.
Regardless of the industry, data dispersion provides critical insights that drive informed decision-making and foster innovation.
Challenges in Measuring Data Dispersion
While data dispersion is invaluable, measuring it accurately comes with challenges. Outliers, data quality issues, and sample size limitations can all impact the reliability of dispersion metrics.
For example, in a dataset with a few extreme values, the range might overstate variability, while variance and standard deviation could be disproportionately affected. Addressing these challenges requires careful data preprocessing, outlier detection, and robust statistical techniques.
Tools and Software for Analyzing Data Dispersion
Modern technology offers a plethora of tools and software for analyzing data dispersion. Popular options include:
- Microsoft Excel: Intuitive and widely used for basic statistical analysis.
- R and Python: Advanced programming languages with extensive libraries for data analysis.
- SPSS and SAS: Comprehensive statistical software for professional use.
These tools empower analysts to calculate dispersion metrics, visualize data, and derive actionable insights with ease.
Visualizing Data Dispersion
Visualization plays a crucial role in understanding data dispersion. Graphical representations, such as histograms, box plots, and scatter plots, make it easier to interpret variability and identify patterns.
For example, a box plot highlights the IQR, median, and outliers, providing a clear snapshot of the dataset’s spread. Similarly, scatter plots can reveal relationships between variables and the extent of dispersion.
Data Dispersion vs. Central Tendency
While central tendency measures, like the mean and median, summarize the data’s central value, dispersion metrics provide context by highlighting variability. Both are essential for comprehensive data analysis, as they offer complementary insights.
For instance, in a dataset with a mean salary of $70,000, high dispersion might indicate significant inequality, while low dispersion would suggest uniformity. Together, these measures paint a complete picture of the dataset’s characteristics.
Future Trends in Data Dispersion Analysis
As data continues to grow in volume and complexity, the importance of data dispersion analysis will only increase. Emerging trends, such as machine learning and artificial intelligence, are integrating dispersion metrics to enhance predictive models and decision-making processes.
Future advancements are likely to focus on real-time dispersion analysis, automated outlier detection, and improved visualization techniques, making data dispersion more accessible and actionable for diverse applications.
FAQs About Data Dispersion
1. What is the main purpose of data dispersion?
Data dispersion measures variability within a dataset, providing insights into the spread and reliability of the data.
2. How is data dispersion different from central tendency?
Central tendency summarizes the central value of a dataset, while dispersion highlights variability, offering a more complete understanding of the data.
3. What are the most common measures of data dispersion?
Common measures include range, variance, standard deviation, and interquartile range (IQR).
4. Why is standard deviation widely used?
Standard deviation is popular because it provides an interpretable measure of spread in the same units as the data.
5. How do outliers affect data dispersion?
Outliers can significantly impact dispersion metrics, such as range and variance, potentially skewing results.
6. Can data dispersion be visualized?
Yes, data dispersion can be visualized using graphs like box plots, scatter plots, and histograms, making it easier to interpret variability.
Conclusion
Data dispersion is a cornerstone of modern data analysis, offering critical insights into the variability and reliability of datasets. By understanding the spread of data, businesses, researchers, and analysts can make more informed decisions, optimize strategies, and uncover hidden patterns.
As technology continues to evolve, the tools and techniques for analyzing data dispersion will become even more sophisticated, empowering users to harness the full potential of their data. Whether you're a seasoned statistician or a curious learner, mastering the concept of data dispersion is an invaluable skill in today’s data-driven world.